Timeout comme protection de votre système
Par Christian Sperandio
- 3 minutes de lecture - 583 motsQuand on parle de système distribué, le terme « disponibilité » revient souvent.
Et souvent, on associe la disponibilité à la scalabilité horizontale. Comme s’il suffisait de multiplier les instances d’un service pour avoir un système disponible.
Avant de continuer, définissons ce qu’est la disponibilité. Un système est disponible s’il répond ET s’il répond dans les temps. Pouvons nous considérer un système comme disponible si son temps de réponse est supérieur à 5 secondes alors qu’il est normalement de 30 ms ? Je fais partie de ceux qui pensent que non 🙂
Quelle peut être la raison de ces différences de temps de réponses ? Du fait qu’un système est composé de plusieurs composants distribués sur le réseau; si un des composants a une faiblesse (de cause interne ou résaux) alors l’ensemble du système en pâti.
Tordons le coup à la solution magique de la scalabilité horizontale. Imaginons deux composants A et B avec B appelé par A de manière synchrone. Si B commence à avoir un problème de ressources, augmentant ses temps de réponse et par induction augmentant ceux de A, en quoi augmenter le nombre d’instances de A va résoudre le problème ?
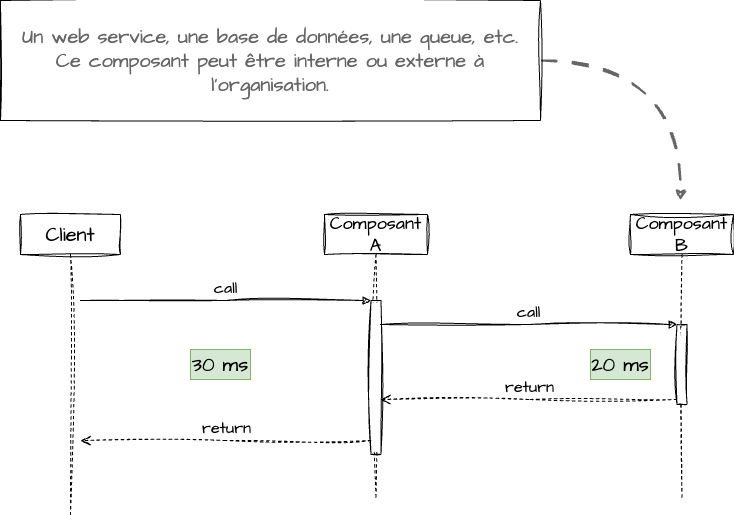
fonctionnement attendu:
Le composant B est en souffrance:
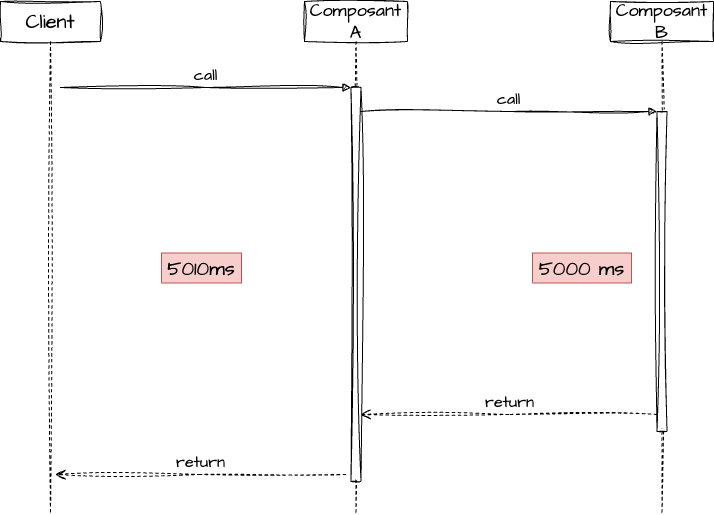
Revenons sur un point: le composant A a mis plus de 5 secondes pour répondre. Ce comportement est-il normal ? On devrait avoir un attribut de qualité donnant le temps de réponse maximale. Cette valeur est importante car elle permet de définir les cas d’anomalies et définir un timeout aux appels vers les autres composants.
Si nous avons 100 ms comme temps de réponses max attendu pour le composant A, alors cela signifie que nous pouvons mettre un timeout sur l’appel vers B (par exemple 80ms). Lorsque ce timeout est atteint, le composant A retourne une erreur (ou une valeur par défaut) à son client et abandonne son appel au composant B.
Utilisation du timeout sur le service B:
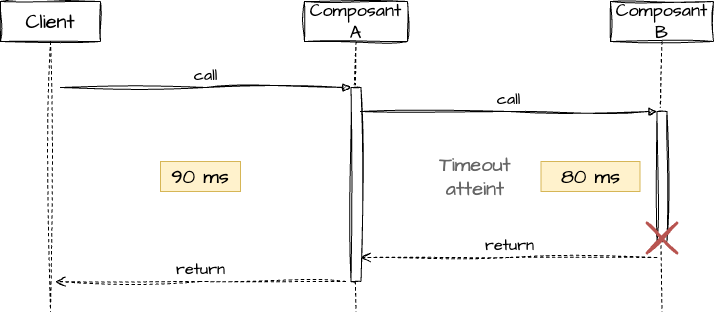
Cette gestion évite au composant A de consommer des ressources inutilement (mémoire, thread, connexion, …) et de bloquer ses clients.
Dans le contexte d’un système distribué, tout appel vers un système externe devrait se faire avec une contrainte de temps, peu importe le service externe: base de données, web service, queue, etc.
J’écris « devrait » et non « doit » car, comme souvent en architecture, il faut s’assurer que la complexité ajoutée en vaille la peine dans le contexte. Si votre système est peu sollicité, genre 1 ou 2 appels par seconde, qu’on accepte une variabilité dans les temps de réponse, nous pouvons considérer que le « hang » est acceptable. Mais, cela doit être explicitement défini dans les attributs de qualité en précisant un temps de réponse moyen, un temps de réponse maximale et un nombre d’appels max sur une période.
Mais le client ne va pas recevoir sa réponse !?
C’est l’une des objections à l’utilisation d’un timeout. Renvoyer la réponse attendue est une chose, s’assurer de la stabilité du système en est une autre et doit être la priorité. A quoi bon répondre à 5 clients si le système s’effondre à cause des 500 requêtes en attente sur le composant A ?
Nous apercevons l’intérêt de mettre en place un timeout pour la préservation du composant A. Mais, il reste beaucoup d’autres points: stratégies de gestion du timeout, risque du transfert de la charge sur les services appelés, etc. Mais, cela fera l’objet d’un autre article 😄
Note: Cet article a également été publié sur LinkedIN .